Recite, Reconstruct, Recollect: Memorization in LMs as a Multifaceted Phenomenon
May 1, 2025
PolyPythias: Stability and Outliers across Fifty Language Model Pre-Training Runs
May 1, 2025
How to visualize training dynamics in neural networks
May 1, 2025
Transcendence: Generative Models Can Outperform The Experts That Train Them
Jan 1, 2024
TRAM: Bridging Trust Regions and Sharpness Aware Minimization
Jan 1, 2024
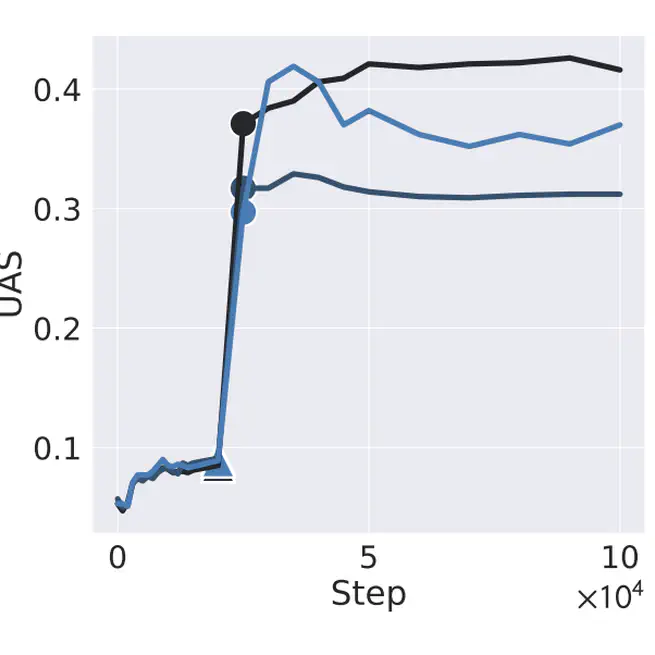
Sudden Drops in the Loss: Syntax Acquisition, Phase Transitions, and Simplicity Bias in MLMs
Jan 1, 2024
First Tragedy, then Parse: History Repeats Itself in the New Era of Large Language Models
Jan 1, 2024
Fast Forwarding Low-Rank Training
Jan 1, 2024
Dynamic Masking Rate Schedules for MLM Pretraining
Jan 1, 2024
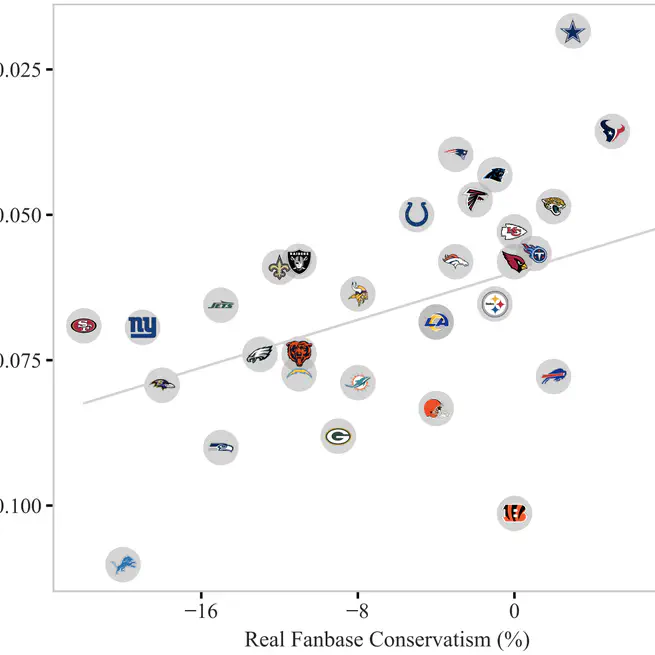
ChatGPT Doesn't Trust Chargers Fans: Guardrail Sensitivity in Context
Jan 1, 2024