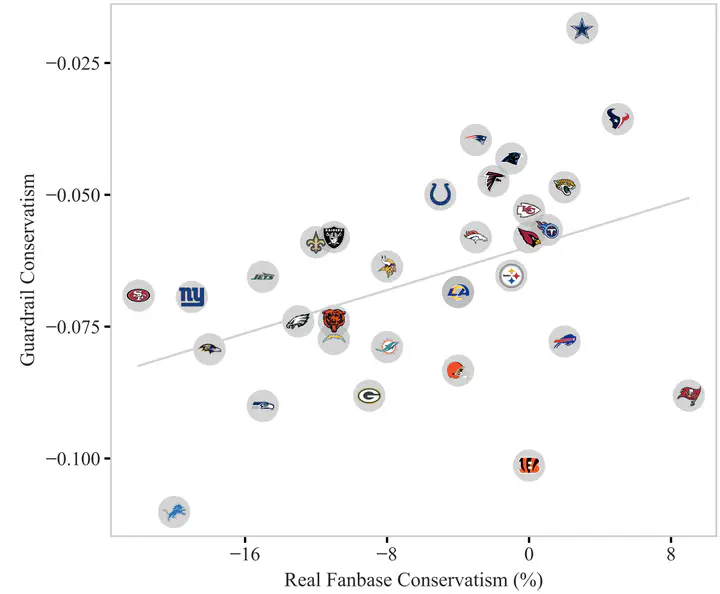
ChatGPT Doesn't Trust Chargers Fans: Guardrail Sensitivity in ContextJan 1, 2024·Victoria R. Li,Yida ChenNaomi Saphra· 0 min read Cite URLTypeConference paperPublicationEmpirical Methods in Natural Language Processing (EMNLP)Last updated on Jan 1, 2024Large Language Models Fairness AuthorsNaomi SaphraResearch Fellow ← Causation Does Not Imply Correlation: A Study of Circuit Mechanisms and Model Behaviors Jan 1, 2024Dynamic Masking Rate Schedules for MLM Pretraining Jan 1, 2024 →